




11:58 | 19.07.23 | Նորություններ | 3113
Meta-ն YerevaNN-ի հետ մշակել է լեզվական մոդելի նորագույն տեխնոլոգիա

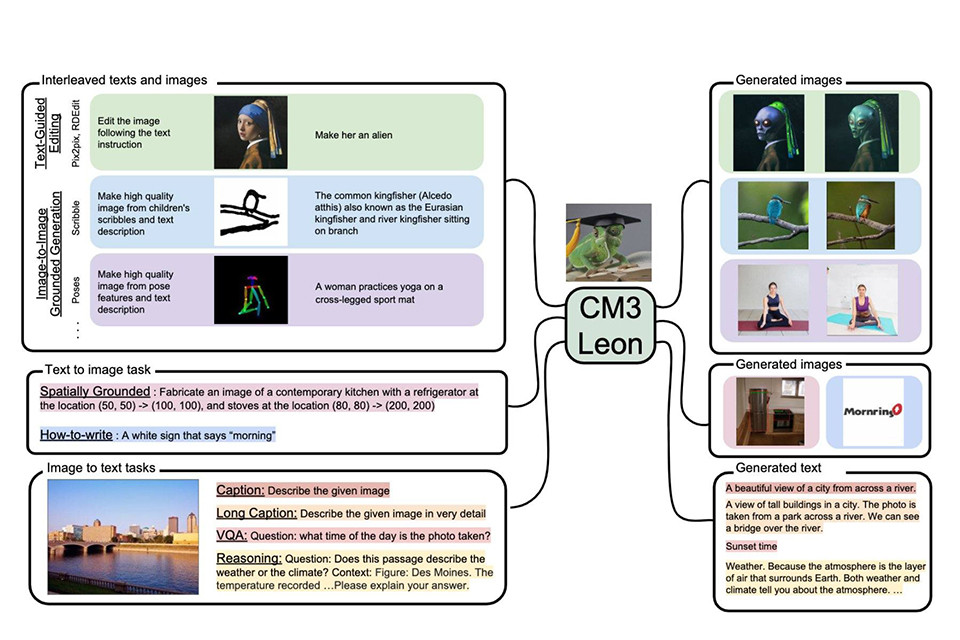
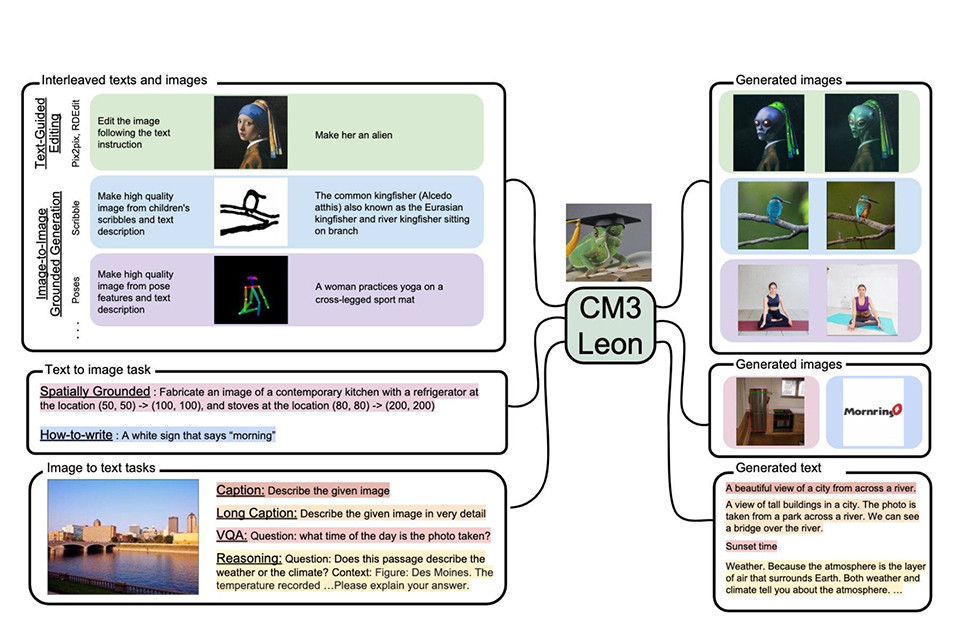
Meta-ն հայտարարել է նոր լեզվի մոդելի CM3Leon-ի ստեղծման մասին, որը վերապատրաստվել է տեքստի եւ պատկերի նշանների վրա:
Հայկական YerevaNN-ը նույնպես իր ներդրումն ունի այս տեխնոլոգիայի մշակման գործընթացում։ YerevaNN-ի համահիմնադիր Հրանտ Խաչատրյանը ներկայացրել է համագործակցության մանրամասները եւ նոր լեզվական մոդելի առավելությունները։
Ըստ նրա՝ CM3Leon-ն սահմանում է նորագույն տեխնոլոգիա՝ տեքստից պատկեր ստեղծելու համար: Այն կարող է ճշգրտորեն կարգավորվել, որպեսզի կատարի բավականին բարդ պատկեր+տեքստային առաջադրանքներ, ներառյալ տեսողական հարցերի պատասխանը, տեքստով առաջնորդվող պատկերի խմբագրումը, մարդկային դիրքով պատկերի ստեղծումը:
«Մետա/Ֆեյսբուք ընկերության մի մեծ թիմ, Արմեն Աղաջանյանի ղեկավարությամբ, ստեղծել է լեզվական մոդել, որը կարողանում է կարդալ ինչպես տեքստ, այնպես էլ պատկերներ, եւ միաժամանակ գեներացնում է ինչպես տեքստ, այնպես էլ պատկերներ: Դա անում է այս պահին հայտնի ամենաբարձր որակով ու ամենաորակյալ diffusion-ի հիման վրա աշխատող մեթոդներից ավելի էներգախնայող է:
Երեւանէնից Հովհաննես Թամոյանը եւս մասնակցություն ունեցավ այս նախագծին՝ ստացված մոդելների վերլուծության հետ կապված ու դարձավ այս հոդվածի համահեղինակ: Այսպիսի համագործակցությունների շնորհիվ մենք աստիճանաբար ինտեգրվում ենք հսկայական նեյրոնային ցանցերի «աշխարհին», սկսում ենք հասկանալ խնդիրներն ու հնարավորությունները, ու դրա հիման վրա պլանավորել մեր առաջիկա տարիների անելիքները:
Հոդվածում տարբեր չափերի նեյրոնային ցանցեր են պատրաստվել, որոնցից ամենամեծը ստանալու համար աշխատել են 512 հատ NVIDIA A100 վիդեոքարտ 25 օր շարունակ: Ամբողջ հոդվածը գրելու ընթացքում գումարային ծախսվել է դրանից 8x շատ հաշվողական ռեսուրս (շուրջ 10000 A100*օր): Այժմ մենք փորձում ենք հասնել նրան, որ Հայաստանում ստեղծվի գոնե 250 A100-ին համարժեք հաշվողական ենթակառուցվածք, որ կարողանանք մոտենալ այս տիպի խնդիրներին»,- գրել է Հրանտ Խաչատրյանը:
Meta-ի ներկայացրած պատկերներում կարող եք տեսնել լեզվական մոդելի աշխատանքի արդյունքները։



Լեզվական մոդելի մասին հրապարակված գիտական հոդվածը կարող եք կարդալ այստեղ։

11:25 | 19.07.23 |
Նորություններ
Վիվա-ՄՏՍ-ը նոր տեխնոլոգիաներ է ներդնում գյուղերում






